تمام حقوق برای خط مهندسی محفوظ است
روشهای یادگیری ماشین (Machine Learning)، سیستمهای مختلف را قادر میکنند که یاد بگیرند، بررسی کنند و به ما پیشنهادهای کاربردی ارائه دهند. این سیستمها به مرور زمان که با دادهها، شبکهها و افراد تعامل دارند، باهوشتر میشوند. با استفاده از رویکردهای یادگیری ماشین و هوش مصنوعی، این سیستمها قادر هستند ما را در حل مسائل مهم، کاربردی و روزمره یاری دهند. غالبا این کار با استفاده از دادههایی انجام میشود که به دلیل حجم زیاد و یا ماهیت نامفهوم، برای ما انسانها چندان قابل استفاده نیست.
تاکنون کاربردهای بسیار زیادی از هوش مصنوعی و یادگیری ماشین را در زندگی روزمره تجربه کردهایم. سرویسهای ایمیل برای تشخیص اسپم از الگوریتمهای یادگیری ماشین استفاده میکنند. سیستمهای پیشنهادگر، مرتبسازی نتایج موتورهای جستجو، تشخیص چهره خندان برای عکاسی خودکار، همگی نمونههای دیگری از کاربردهای یادگیری ماشین هستند.

ابزارها و روشهای مبتنی بر یادگیری ماشین، بر خلاف سایر ابداعات و اختراعات بشر، برای رفع محدودیتها و نیازهای فیزیکی نیستند، بلکه هدف آنها ساختن سیستمهایی است که به جای انسان بیاندیشند، یاد بگیرند و یاد بدهند.
در طی یک دهه آینده، به نظر میرسد که ما شاهد استفاده هر چه بیشتر یادگیری ماشین در طراحی سیستمهای دارای تعامل با انسان خواهیم بود.
یادگیری ماشین چیست؟
این شاخه به این معنا است که ماشین بتواند برنامه، ساختار یا دادههایش را بر اساس ورودیها یا در پاسخ به اطلاعات خارجی، به نحوی تغییر دهد که رفتارش به آن چه از او انتظار میرود نزدیکتر شود، به عبارت دیگر میتوان گفت یعنی قدرت تجزیه تحلیل داشته باشد.

یادگیری ماشین سالهاست که توسط شرکتهای بزرگ در ابعاد کوچک استفاده میشود. مثلا آمازون با رصد کلیکها و علاقهمندیهای افراد سعی در یافتن سلیقههای فرد کرده و تبلیغاتی متناسب با آن برای وی نشان میدهد، گوگل در زمینه جستجوهای اینترنتی و فیسبوک در زمینه شبکههای اجتماعی اقدام مشابه را انجام میدهد و پستهای مورد علاقه افراد را برایشان به نمایش در میآورد.
در این نوشتار قصد داریم به معرفی چند الگوریتم هوش مصنوعی بپردازیم که در زمینه یادگیری ماشین نیز بسیار پرطرفدار هستند.
الگوریتمهای یادگیری ماشین
الگوریتمهای یادگیری ماشین به سه دسته زیر تقسیم بندی میشود:
- یادگیری نظارتی
- یادگیری غیر نظارتی
- یادگیری تقویتی
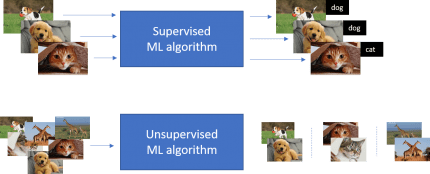
یادگیری نظارتی (Supervised ML)
در روش یادگیری با نظارت، از دادههای با برچسبگذاری برای آموزش الگوریتم استفاده میکنیم. دادههای دارای برچسب به این معنی است که داده به همراه نتیجه و پاسخ موردنظر آن دردسترس است.
برای نمونه اگر ما بخواهیم به رایانه آموزش دهیم که تصویر سگ را از گربه تشخیص دهد، دادهها را به صورت برچسبگذاری شده برای آموزش استفاده میکنیم. به الگوریتم آموزش داده میشود که چگونه تصویر سگ و گربه را طبقهبندی کند. پس از آموزش، الگوریتم میتواند دادههای جدید بدون برچسب را طبقهبندی کند تا مشخص کند تصویر جدید مربوط به سگ است یا گربه. یادگیری ماشین با نظارت برای مسائل پیچیده عملکرد بهتری خواهد داشت.
یکی از کاربردهای یادگیری با نظارت، تشخیص تصاویر و حروف است. نوشتن حرف A یا عدد ۱ برای هر فرد با دیگری متفاوت است. الگوریتم با آموزش یافتن توسط مجموعه دادههای دارای برچسب از انواع دستخط حرف A و یا عدد ۱، الگوهای حروف و اعداد را یاد میگیرد. امروزه رایانهها در تشخیص الگوهای دست خط از انسان دقیقتر و قدتمندتر هستند.
در ادامه تعدادی از الگوریتمها که در یادگیری نظارتی مورد استفاده قرار میگیرد شرح داده میشود.
درخت تصمیم (ِDecision Tree)
ساختار درخت تصمیم در یادگیری ماشین، یک مدل پیش بینی کننده میباشد که حقایق مشاهده شده در مورد یک پدیده را به استنتاج هایی در مورد هدف آن پدیده پیوند میدهد. درخت تصمیم گیری به عنوان یک روش به شما اجازه خواهد داد
مسائل را بصورت سیستماتیک در نظر گرفته و بتوانید نتیجه گیری منطقی از آن بگیرید.
دستهبندی کننده بیز (Naive Bayes classifier)
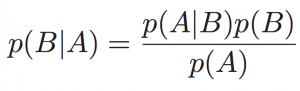
دستهبندیکننده بیز در یادگیری ماشین به گروهی از دستهبندیکنندههای ساده بر پایه احتمالات گفته میشود که با متغیرهای تصادفی مستقل مفروض میان حالتهای مختلف و براساس قضیه بیز کاربردی است. بهطور ساده روش بیز روشی برای دستهبندی پدیدهها، بر پایه احتمال وقوع یا عدم وقوع یک پدیدهاست.
کمینه مربعات
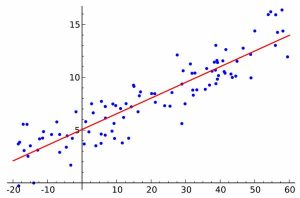
در علم آمار، حداقل مربعات معمولی یا کمینه مربعات معمولی روشی است برای برآورد پارامترهای مجهول در مدل رگرسیون خطی از طریق کمینه کردن اختلاف بین متغیرهای جواب مشاهده شده در مجموعه داده است. این روش در اقتصاد، علوم سیاسی و مهندسی برق و هوش مصنوعی کاربرد فراوان دارد.
رگرسیون لجستیک (logistic regression)
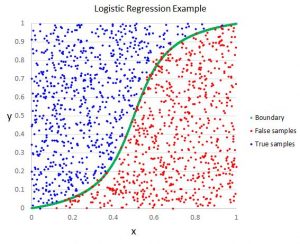
زمانی که متغیر وابسته ی ما دو وجهی (دو سطحی مانند جنسیت، بیماری یا عدم بیماری) است و میخواهیم از طریق ترکیبی از توابع منطقی دست به پیش بینی بزنیم باید از رگرسیون لجستیک استفاده کنیم. اندازه گیری میزان موفقیت یک کمپین انتخاباتی، پیش بینی فروش یک محصول یا پیش بینی وقوع زلزله در یک شهر، چند مثال از کاربردهای رگرسیون لجستیک است.
ماشین بردار پشتیبانی (Support vector machines )
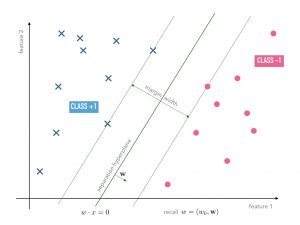
یکی از روشهای یادگیری نظارتی است که از آن برای طبقهبندی و رگرسیون استفاده میکنند. مبنای کاری دستهبندی کننده SVM دستهبندی خطی دادهها است و در تقسیم خطی دادهها سعی میکنیم خطی را انتخاب کنیم که حاشیه اطمینان بیشتری داشته باشد.
از طریق SVM میتوان مسائل بزرگ و پیچیدهای از قبیل شناسایی تمایز انسان و باتها در سایتها، نمایش تبلیغات مورد علاقه کاربر، شناسایی جنسیت افراد در عکسها و… را حل کرد.
یادگیری غیر نظارتی (Unsupervised ML)
در این نوع از الگوریتمها، متغیر هدف نداریم و خروجی الگوریتم نامشخص است. بهترین مثالی که برای این نوع از الگوریتم ها می توان زد، گروه بندی خودکار (خوشه بندی) یک جمعیت است. مثلاً با داشتن اطلاعات شخصی و خریدهای مشتریان، به صورت خودکار آنها را به گروه های همسان و هم ارز تقسیم کنیم. در یادگیری بدون نظارت، الگوریتمها از روشهای تخمین مبتنی بر آمار استنباطی برای شناسایی الگوها و همبستگی و ارتباط میان دادههای خام و بدون برچسب استفاده میکند.

هنگامیکه الگوها شناسایی شوند الگوریتم از آمار برای شناسایی مرز درون مجموعه دادهها بهره میگیرد. دادههای با الگوهای مشابه در یک گروه طبقهبندی میشوند. با ادامه یافتن فرآیند طبقهبندی دادهها، الگوریتم الگوی مجموعه داده را درک میکند و برای دادههای جدید پیشبینی انجام میدهد.
در ادامه تعدادی از الگوریتمها که در یادگیری غیر نظارتی مورد استفاده قرار میگیرد شرح داده میشود.
الگوریتم خوشه بندی (Cluster analysis)
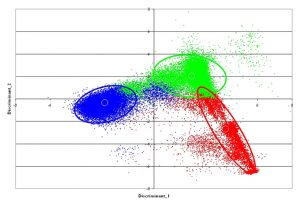
خوشهبندی یا آنالیز خوشه در آمار و یادگیری ماشینی، یکی از شاخه های یادگیری بینظارت میباشد و فرآیندی است که در طی آن، نمونهها به دستههایی که اعضای آن مشابه یکدیگر میباشند تقسیم میشوند که به این دسته ها خوشه گفته میشود. بنابراین خوشه مجموعه ای از اشیاء میباشد که در آن اشیاء با یکدیگر مشابه بوده و با اشیاء موجود در خوشههای دیگر غیر مشابه میباشند.
تحلیل مولفههای اصلی (Principal Component Analysis)
تبدیلی در فضای برداری است که بیشتر برای کاهش ابعاد مجموعهٔ دادهها مورد استفاده قرار میگیرد. تحلیل مولفههای اصلی یک تبدیل خطی متعامد است که داده را به دستگاه مختصات جدید میبرد به طوری که بزرگترین واریانس داده بر روی اولین محور مختصات، دومین بزرگترین واریانس بر روی دومین محور مختصات قرار میگیرد. به این ترتیب مولفههایی از مجموعه داده را که بیشترین تاثیر در واریانس را دارند حفظ میکند.
تجزیه مقادیر منفرد (Singular Value Decomposition)

تجزیه مقدارهای منفرد قدمی اساسی در بسیاری از محاسبات علمی و مهندسی بهحساب میآید. اولین سیستم های تشخیص چهره با استفاده از الگوریتم تجزیه مقادیر منفرد (SVD) و تحلیل مولفه های اصلی (PCA) بوجود آمدند.
تحلیل مولفههای مستقل (Independent Component Analysis)
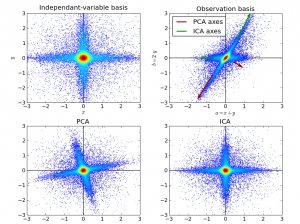
تحلیل مولفههای مستقل روشی است برای جداسازی سیگنال به مجموع چند سیگنال دیگر به طوری که سیگنالهای حاصل مستقل و دارای توزیع غیر گوسی باشند. این روش یک مورد از جداسازی کور منابع یا blind source separation میباشد. معمولا مسئله در حالت سادهتری در نظر گرفته میشود که هیچگونه تاخیری در دریافت سیگنالها وجود ندارد.
یادگیری تقویتی (Reinforcement ML)
نوع سوم از الگوریتمها که شاید بتوان آنها را در زمره الگوریتم های بدون ناظر هم دسته بندی کرد. در این نوع یک ماشین (در حقیقت برنامه کنترل کننده آن)، برای گرفتن یک تصمیم خاص آموزش داده میشود و ماشین بر اساس موقعیت فعلی (مجموعه متغیرهای موجود) و اکشن های مجاز (مثلا حرکت به جلو ، حرکت به عقب و …) یک تصمیم را می گیرد که در دفعات اول، این تصمیم میتواند کاملاً تصادفی باشد و به ازای هر اکشن یا رفتاری که بروز می دهد، سیستم یک فیدبک یا بازخورد به او میدهد و از روی این فیدبک ماشین متوجه میشود که تصمیم درست را اتخاذ کرده است یا نه که در دفعات بعد در آن موقعیت، همان اکشن را تکرار کند یا اکشن و رفتار دیگری را امتحان کند.
با توجه به وابسته بودن حالت و رفتار فعلی به حالات و رفتارهای قبلی، فرآیند تصمیم گیری مارکوف ، یکی از مثالهای این گروه از الگوریتمها میتواند باشد . الگوریتمهای شبکههای عصبی هم میتوانند ازین دسته به حساب آیند. منظور از کلمه تقویت شونده در نام گذاری این الگوریتمها هم اشاره به مرحله فیدبک و بازخورد است که باعث تقویت و بهبود عملکرد برنامه و الگوریتم میشود .
میتوان گفت یادگیری تقویتی مانند یادگیری مبتنی بر آزمون و خطای انسان است. یادگیری تقویتی برای ایجاد استراتژیها کاربرد دارد. کاربرد یادگیری تقویتی در آموزش بازیها به رایانهها است. برای نمونه میتوان شرکت DeepMind را نام برد که در سال ۲۰۱۴ توسط گوگل خریداری شد. این شرکت تلاش میکند تا به الگوریتم خود، بازی قدیمی و معروف آتاری (Atari) را آموزش دهد. آلفاگو (AlphaGo) سامانه هوش مصنوعی که توسط گروه DeepMind گوگل برای انجام بازی Go طراحی شده توانست قهرمان جهانی این بازی را شکست دهد.
منبع: خط مهندسی
نگارش: خط مهندسی
دست گلتون درد نکنه عالی بود واقعا، (رفتم یه سایتی تو مقاله یادگیری ماشین نوشته: الگوریتم فلان بر فلان رجحان یافت! ) برای ترجمه فنی تون هم ویژه تشکر.پاینده باشید
سلام علی جان
خوشحالیم که مقاله براتون مفید بوده
موفق باشید
سلام. بابت متن خوبی که ارائه کردید سپساسگزارم . آیا امکانش هست متن را برایم ارسال کنید. ممنون
Email: [email protected]
ممنون از نظر مثبتتون، محمدرضا عزیز شما میتونید متن رو از روی سایت کپی کنید و با ذکر منبع مانعی وجود ندارد.
سلام خسته نباشید من دارم تلاش میکنم که یاد بگیرم لرنینگ و دیپ لرنینگ و منبع خاصی رو میتونید معرفی کنید
ممنون
سلام و درود بسیار سایت عالی دارید و من عاشق این سایت شدم و سعی می کنم هر سه روز یکبار به مقالات تکنولوژِی هوش مصنوعی و بیگ دیتا و الگوریتم های آن سر بزنم و بخوانم
شما می توانید در زمینه های بالا و مخصوص بیگ دیتا و هوش مصنوعی کتاب های خارجی ترجمه کنید و در همین سایت و دیجی کالا به فروش برسانید قطعا با موج خریدارن زیادی روبه رو می شوید که یکی از آنها خودم هستم
سلام، روز بخیر
ممنونم بابت مطالب ارائه شده در صفحه، بسیار عالی بودند.
بنده روی یک مقاله کار میکنم که باید تعدادی شاخص کلیدی در مسئله انتخاب تامین کننده رو شناسایی کنم و در ۴ بخش چابک، سبز، تاب آور و ناب تقسیم بندی کنم. شاخص های بسیار زیادی توی مرور ادبیات پیداکردم که هرکدام به نحوی مهم و تاثیر گذار هستند. سوال بنده اینه که اگر بخوام از بین این شاخص ها تعدادی کمی رو انتخاب و دسته بندی بکنم و به عنوان شاخص های اصلی در مسئله استفاده کنم، شما کدوم الگوریتم ماشین لرنینگ رو توصیه میکنید برای انجام این کار؟؟